
What is an Azure Storage Account?
An Azure storage account creates a globally unique namespace that contains the base parameters for what the storage account will be used for and where it is located. Typically the storage account contents will match some performance, locational, security or billing requirement or a combination of these, therefore an Azure subscription may have more than one storage account if requirements differ. Storage can be used for any application you can think of for a vast array of structured, semi-structured and unstructured data.
What are the main things you need to consider when creating a storage account.
Firstly, you need to pick a storage account name. It has to be unique across all of Azure and be between 3 and 23 characters long, lowercase and numbers only. The name will form part of the URI for accessing the storage account.
Next you need to consider then pick your region: the geographic location of the datacentres that will be hosting your data. Generally this will be down to where the closest region is to your customers or users of the data but other factors may be considered such as cost. There is ability do deploy to municipal areas dotted around the world called Edge zones but this is isn’t as popular.
Another important choice is performance. Choosing standard will give you access to general purpose v2. This is the most popular option and supports blob storage (including data lake storage), queue storage, table storage and Azure file storage. Choosing premium gives you premium block blobs, page blobs and file share storage. Premium storage is higher has higher throughput and/or lower latency but you cannot have a mix of storage types such as block blobs and file shares in the same storage account.
There are legacy storage accounts: General purpose v1 and blob storage but these are not considered best practice for the vast majority of cases are deprecated with a retirement date of 31st August2024.
The last major decision is the redundancy level you require which are as follows:
Locally-redundant Storage (LRS) stores 3 copies of the data in a single datacentre in the selected region. It is the lowest option and provides at least 99.999999999% (11 9’s) durability and at least 99.9% availability for read and write requests using the hot tier (access tiers covered later).
Zone-redundant Storage (ZRS) distributes 3 copies of the data into different data centres in the same region (availability zones). Each zone will have independent power, networking and cooling but still be close enough together to have really low latency. The target distance apart is around 300 miles where possible. This option provides at least 99.9999999999% (12 9’s) durability and at least 99.9% availability for read and write requests using the hot tier*.
Geo-redundant storage (GRS) stores 3 copies of the data in a data centre in one region, like LRS, but then asynchronously copies to another region (the paired region, most regions have one) and have 3 copies in a data centre there too. GRS offers durability for storage resources of at least 99.99999999999999% (16 9’s) over a given year. Read and write availability is at least 99.9%*.
Read-access-geo-redundant (RA-GRS) is the same replication method as GRS but you can read the data from the secondary region. This could have advantages from bringing the data close to the user scenario and means data can be accessed without having to initiate a failover, as would be the case for plain GRS (or GZRS). By adding read access to the secondary location, this increases read availability to at least 99.99%*.
Geo-zone-redundant storage (GZRS) as the same suggests is a combination of ZRS and GRS, where there are 3 copies of the data spread over availability zones in the primary region and 3 copies in a single data centre at the secondary location (LRS arrangement). The durability for this method is also at least 99.99999999999999% (16 9’s). Read and write availability is at least 99.9%*.
Read-access geo-zone-redundant storage (RA-GZRS) enhances GZRS by allowing read access at the secondary location without a failover. By adding read access to the secondary location, this increases read availability to at least 99.99%*.
For premium storage, only LRS and ZRS options are available due to the performance requirement. Azure managed disks and Azure elastic SAN also are limited to LRS and ZRS.
* 99% for cool tier.
Block blobs, append blobs, page blobs, queue storage, table storage and Azure file storage. What are the different storage types and when might I use them?
Blobs are stored in a security boundary called a container, where you can set access permissions. There are 3 types of blob: block, append and page. They can be accessed by users and client apps via http or https. There are multiple methods for access including via the Azure Storage REST API, Azure PowerShell, Azure CLI, or an Azure Storage client library which are available for a number of popular programming languages. Blob storage is a flat filesystem but can be made to emulate a folder structure by prefixing the filename with a would-be folder followed by “/” for example images/hello.jpg.
Block blobs are a popular storage type in any cloud provider. They are ideal for storing any unstructured files such as images, text, and video. Typically these will be used to host content for a website or app or streaming audio and video. Blobs can be as big are 190.7TiB.
Next is append blobs which are optimised for appends to files as opposed to random access writes – useful for things like logging. The maximum size for an append blob is slightly more than 195 GiB.
Page blobs store virtual hard drive (VHD) for Azure virtual machine disks and can be up to 8 TiB in size. Although this was once the way for WM disks, this method (unmanaged disks), is being deprecated, with managed disks being a simpler to setup option where the storage account is abstracted away and size and performance are easier to adjust.
Queue storage is used for storing messages that are up to 64Kb in size. The queue can run into millions or messages, the maximum governed by the entire storage account storage limit. Queues help decouple parts of of an application which is ideal for architecting in the cloud. For example, messages are created by one part of an application, perhaps a .net app using the queue storage client library, which can then be processed by another system component in the application architecture, such as Azure functions. For messages over 64Kb, ordering guarantee (FIFO) and other more advanced functionality, then consider Azure Service Bus queues.
Lastly there is table storage. This is used to store tabular data, which is semi-structured, following no fixed schema. Often this data scenario is now stored in Cosmos DB which allows for more performance and scale, but there may be cases where table storage in a storage account is preferable, such as cost.
What is Azure Data Lake Storage Gen2?
Azure data lake storage Gen2 (ADLS Gen2) is built on blob storage but selecting the hierarchical namespace when creating the storage account unlocks the features of ADLS Gen2.
You can turn data lake on when creating your storage account, using either general purpose v2 or premium block blob. Being a blob storage, you can store files of any type whether structured, semi-structured or unstructured. Although, a data lake is used a lot in data analytics which would generally be structured or semi structured.

One of the biggest differences between blob and data lake is the use of a directory structure, useful in ELT (extract, load & transform) data pipelines for big data analytics. By having folders, you can bring, in addition to RBAC, POSIX style Access Control Lists (ACLs). Additionally Microsoft Purview can create security policies for files and folders, based on classifications.
As well as the Azure Blob API, developers and data engineers can use the ABFS driver for Hadoop that communicates with the DFS API to work with a hierarchical directory structure.
ADLS Gen2 being built on blob offers most of the benefits of a standard or premium blob service such as access tiers, redundancy levels, NFS & SFTP. There are some limitations when using ADLS Gen2 over blob so check the latest official documentation for what they are currently.
ADLS Gen 1 is to be retired on the 29th February 2024, so was not described here for that reason.
What security considerations does an Administrator need to factor in when managing a storage account?
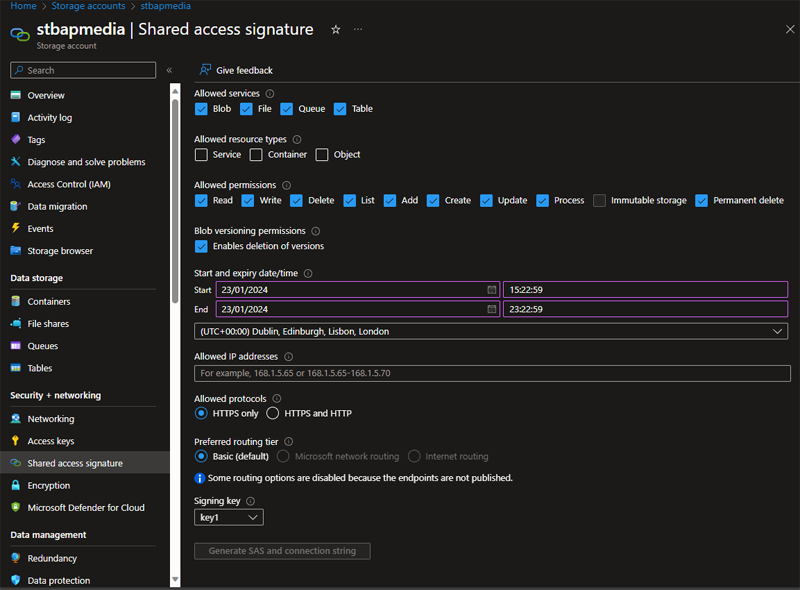
We need to secure access to the data with credentials, whether access is via a user or an application. There is an overarching authorisation method which is a storage account key. These are the “keys to the kingdom” which will give access to everything in the storage account and so are not considered best practice. Each account has two storage account keys that can be rotated manually or automatically if the keys are integrated with Azure key vault. The idea of having 2 keys is your application can switch to the 2nd key whilst you rotate the first. An evolution of this, and considered a good solution, especially when there are third party users or apps involved is shared access signatures (SAS). Shared access signatures allow you to build a URI that gives granular and time limited access to account and/or data plane functions. Once a signature has been created you cannot revoke it until it expires but you can rotate the storage account key which was used to generate it (key 1 or key 2). A generally best practice authorisation method when you have users or managed identities in your tenant that require account, container or data rights, is Access control (IAM) which works under Azure role-based access control (RBAC), prevalent throughout all Azure services. With RBAC, you can assign users, groups or managed identities to an Azure created or custom role. This allows fine grained access to control and data plane features.
Moving onto networking considerations, starting with encryption in transit. When creating a new storage account, the setting, require secure transfer, is on as default and should be left that way. This setting disables http access to the data via the API and only allows encrypted connections to SMB 2.1 or SMB 2.3. Unless there is a specific use case, it is recommended to keep this setting on. Deactivating will allow http access as well as https. Note: currently, using a custom domain will not allow you to use secure transfer so the setting will not have any affect when using a custom domain. Every storage account has a firewall. There are three settings, disabled, which blocks all traffic and so the only way to access the data is via a private endpoint and there is enabled from all networks, which is great if the storage account is used for hosting website assets, images for a product catalogue for example. The third option Enabled from selected virtual networks and IP addresses does just that; allows the administrator to specify which virtual networks can access the storage account, also specify access via IP address or CIDR range, and finally by Azure service type and scope such as “Microsoft.EventGrid/Topics in this resource group”. If specifying a virtual network, you must enable the service endpoint on the virtual network(s) you specify, applying the Microsoft.Storage for regional storage accounts or Microsoft.Storage.Global for cross-region storage accounts. Some options you can also consider on the storage account firewall. There are some some firewall exceptions you can turn on, such as “allow read access to storage logging from any network”. Also, you can specify Microsoft routing or Internet routing, will determine where the traffic traverses to connect the client and storage account. A really good solution for storage account security is to select disabled on the firewall settings and then set up a private endpoint. A private endpoint works over Azure private link, where the storage service traffic travels on the Microsoft backbone and has a special network interface in a subnet you select, which is assigned an IP address from your subnet’s CIDR range. Once the private endpoint has been established in your chosen subnet, you can setup connectivity beyond that subnet or VNet with networking features such as VNet peering, custom routes and on prem connectivity via VPN or ExpressRoute.
Lastly in this section we have Encryption. We’ve already discussed encryption in transit in the networking section able. Azure storage also provides encryption at rest with a technology called Storage Service Encryption (SSE). This is on all storage accounts and cannot be deactivated. All data is stored using 256-bit AES encryption and is FIPS 140-2 compliant. Data is stored using Microsoft managed keys but an administrator can also use customer managed keys which must be stored in Azure Key Vault (AKV)or Azure Key Vault Managed Hardware Security Model (HSM) or customer provided keys which will allow the client to provide the key on request to the blob storage – keys can be stored in the Azure key vaults (standard or HSM) or another key store. As well as whole accounts you can specify encryption scopes for blob storage at the container or for an individual blob. Another encryption options available is infrastructure encryption, for double encryption of data (infrastructure and service).
What backup and recovery options are available?
To restore files accidentally or maliciously deleted, you can turn on soft delete. By setting a retention period for containers from 1 to 365 days. If a file gets deleted, you have until the retention period to undelete the file.
To automatically retain copies of a file before the latest amendment, you can turn on blob versioning. To restore a previous version, you select the version you wish to restore to recover your data if it’s modified or deleted. Blob versioning is often used alongside soft delete to form an overall data protection strategy. Storing lots of versions carries a cost consideration and can create latency when running a list blob command, for this it is recommended to change access tiers or delete older versions using lifecycle management which is covered later in this document.
You can also take a snapshot of a blob. This is a manual process that appends the blob URI with a DateTime value. Snapshots exist until they are independently deleted or as part of a delete blob operation. Versioning maybe best practice but at the time of writing, versioning doesn’t work with ADLS Gen2, whereas snapshots do (in preview).
If you are using geo redundant storage (GRS / RA-GRS / GZRS / RA-GZRS) and the primary region suffers a failure, you can initiate a customer managed failover where upon completion the secondary region becomes the primary and the old primary, the secondary. If Microsoft detects a failure at the primary region deemed to be severe enough, the system may initiate a failover automatically without customer intervention. This is called a Microsoft-managed failover.
For business-critical data that must not be changed or deleted after being created, you can apply a WORM (Write Once, Read Many) state called immutable storage. Set at account, container or blob version level, you can set a time-based retention policy. Blobs can be created and read, but not modified or deleted. After the retention period has expired, objects can be deleted but not overwritten. There is also a legal hold type of immutable storage, which can be set at blob level. Legal hold prevents deleting or modifying an object until the legal hold is explicitly cleared. If any container has version-level immutability enabled, the storage account is protected from deletion, likewise a container cannot be deleted whilst a blob has an immutable storage policy active.
If you enable soft delete, change feed and blob versioning on your storage account, you can take advantage of point-in-time restore for block blobs, where you set the maximum restore point in days in the storage account. From then, if you need to restore a file (or entire container, or virtual directory), you can choose a restore date and time in UTC.
To protect the storage account itself from being removed or its configuration modified, you can apply an Azure Resource Manager lock. Locks come in two types; CannotDelete lock prevents the account being deleted but the configuration settings can be changed whereas ReadOnly lock prevents changing the configuration or deleting the storage account. Both locks still allow the account configuration to be read.
NB Some of these features will not work when hierarchical namespace is enabled, so check the latest official documentation to ensure what data protection options you have if that applies to your configuration.
What services can import or export volumes of data to or from Azure storage?
There are various ways to get data in and out of Azure storage, let’s have a look at some of them. Firstly, if you are only transferring a small amount of data, you can use a command line or graphical interface tool.
For command line, you can use Azure CLI, PowerShell or the dedicated AzCopy program, which supports concurrency and parallelism, and the ability to resume copy operations when interrupted.
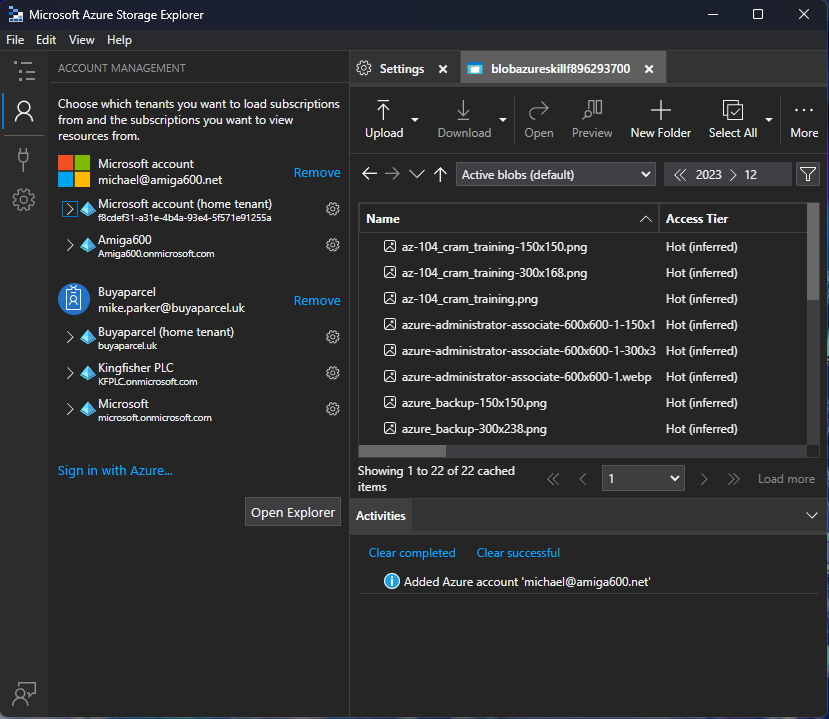
If you want to use a GUI, then you can upload and download files in the Azure portal, or there is Azure Storage Explorer, available on Linux, Mac and Windows.
If you are doing a massive data transfer exercise or moving data from somewhere with little or no Internet access, you may want to use the Azure Import/Export service which allows you to prep and send SATA HDD or SSDs to Microsoft to securely upload or download data. For larger data still, Azure has physical appliances it can ship to and from customers to do data transfers; Data Box Disk and Data Box Heavy which are encrypted and logistics are done via an approved carrier.
For regular transfers of big data, you may want to use a service such as Azure Data Factory where you build data pipelines between source and sink and can perform in-transit transformations as well as other features. Similarly, you can use pipelines and activities Azure Synapse Analytics. Microsoft also have Azure Data Box Gateway which is a virtual appliance you can run in your co-location datacentre or on premises. Azure Data Box Gateway transfers data to and from Azure via NFS and SMB protocols.
If you need a programmatic ability to transfer data, then the Data movement library for .net & .net core is an option or there is the Azure Storage REST API and Azure blob storage libraries for .net, Java, C++, Python, Go & JavaScript. If you have static website mode activated, you can deploy your static website assets via Terraform.
There are other tools, that can be used, including AdlCopy, Distcp, Sqoop, PolyBase, Hadoop command line, Azure Data Factory integration runtime and the new Microsoft Fabric data analytics platform.
Any best practice or cost saving tips?
A good first step is considering the amount of redundancy you need for a given workload and break the varying requirements into different storage accounts. For example, for a customer facing global website may benefit from having data in two regions and so RA-GRS or RA-GZRS maybe ideal, but if you have some internal documents primarily used in one region, LRS or ZRS may have all the redundancy required, at a lower cost.
Access tiers are designed to get maximum value for money, depending on the access requirements of your data. The four tiers are hot, cool, cold and archive. Hot tier will be the most expensive to store but cost less to access and transact with the data, whilst on the other extreme, archive tier is cheap offline storage for backup or compliance date storage, but to gain access will come with a higher cost, this data should be stored for a minimum of 180 days. In the middle, there is cool tier, used for infrequently accessed or modified data, which should be stored for a minimum of 30 days. For rarely accessed data that still needs to remain online, there is cold storage which should be stored for a minimum of 90 days. If you move anything to archive tier, note that it will take hours to move it back to hot, cool or cold tier and isn’t modifiable whilst in the archive tier. Blobs will incur an deletion penalty if they are deleted or moved to a different tier before the minimum number of days required by the tier. A storage account has a default access tier, which is inherited by all containers contained in the account but can be changed at blob level.
Developing on the access tiers concept, Azure has functionality to automate the tiers of blobs. This is called lifecycle management. This allows blobs to move to different access tiers or be deleted, depending on the rules you create. This is best practice for cost and data compliance. Purposes. By using lifecycle management, you take some of the guesswork out of when blobs are candidates to change to a more suitable tier. For example, a pdf of a manual for a product on a manufacturer’s website could be read and updated regularly so would be ideal to be in the hot tier, but as the model is discontinued and time passes, it could be accessed so infrequently that moving to cool or cold would be better suited, which can be done automatically using lifecycle management. At some point, the data maybe archived or deleted, which can also be automated. Lifecycle management policies can be applied to block and append blobs in general-purpose v2, premium block blob, and Blob Storage accounts. System containers such as $logs or $web are not affected by these policies.
Reserved capacity allows users to commit to storage in units of 100 TiB and 1 PiB (higher discounts for 1 PiB blocks), for a one-year or three-year term. Committing gives a discount that will vary depending on the length of time you reserve for, the region, the total capacity you reserve, the access tier and type of redundancy that you are using. It is worth doing the analysis on the Azure pricing calculator to illustrate the discount and commitment spend involved.
Azure pricing calculator will illustrate reserved capacity vs PAYG costs
There are options you can toggle in your storage account which carry extra charges, for example SFTP, which is charged by the hour. To reduce the cost, consider having an Azure automation runbook to toggle the service off and on depending on the hours it is required in your organisation. In this scenario, you could also consider using the Azure storage explorer application for your team and therefore would not require the cost or management overhead of using SFTP.
How can I find out more information?
There are lots of other parts of Azure storage accounts you can investigate, depending on your requirements. We could have covered them here but this post could have been a book. Notable key focus areas to consider are monitoring, Defender for cloud, static website mode, Front door & CDN, custom domain names, Resource sharing (CORS) and blob inventory.
If you want to be certified in Azure storage, then look at the DP-203 exam which, upon passing will give you the Microsoft Certified: Azure Data Engineer Associate certification. As well as Azure storage and ADLS Gen2, the certification covers Azure Data Factory, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hubs and Azure Databricks.